










Laxmikant Kale
Faculty
kale at illinois.edu
217-244-0094
Profile
Laxmikant (Sanjay) Kale is the Paul and Cynthia Saylor Professor of Computer Science and leader of the Parallel Programming Laboratory. Here is his proper home page, and his
resume in
pdf format.
Research Areas
Papers
22-08
2022
[Paper]
[Paper]
Improving Communication Asynchrony and Concurrency for Adaptive MPI Endpoints [ExaMPI 2022]
22-07
2022
[Paper]
[Paper]
Runtime Techniques for Automatic Process Virtualization [P2S2 2022]
22-06
2022
[Paper]
[Paper]
ParaTreeT: A Fast, General Framework for Spatial Tree Traversal [IPDPS 2022]
22-05
2022
[Paper]
[Paper]
Improving Scalability with GPU-Aware Asynchronous Tasks [HIPS 2022]
22-04
2021
[Paper]
[Paper]
Performance Evaluation of Python Parallel Programming Models: Charm4Py and mpi4py [ESPM2 2021]
22-03
2022
[Paper]
[Paper]
Optimizing Non-Commutative Allreduce over Virtualized, Migratable MPI Ranks [APDCM 2022]
22-02
2021
[Paper]
[Paper]
Accelerating Messages by Avoiding Copies in an Asynchronous Task-based Programming Model [ESPM2 2021]
22-01
2021
[Paper]
[Paper]
Enabling Support for Zero Copy Semantics in an Asynchronous Task-Based Programming Model [Asynchronous Many-Task Systems for Exascale Workshop 2021]
21-01
2021
[Paper]
[Paper]
GPU-aware Communication with UCX in Parallel Programming Models: Charm++, MPI, and Python [AsHES 2021]
20-04
2020
[Paper]
[Paper]
Achieving Computation-Communication Overlap with Overdecomposition on GPU Systems [ESPM2 2020]
20-03
2020
[Paper]
[Paper]
Scalable molecular dynamics on CPU and GPU architectures with NAMD [J. Chem. Phys. 2020]
20-02
2020
[Paper]
[Paper]
End-to-end Performance Modeling of Distributed GPU Applications [ICS 2020]
19-05
2019
[Paper]
[Paper]
Fine-Grained Energy Efficiency Using Per-CoreDVFS with an Adaptive Runtime System [IGSC 2019]
19-03
2019
[Paper]
[Paper]
An Adaptive Non-Blocking GVT Algorithm [ACM SIGSIM PADS 2019]
19-02
2019
[Paper]
[Paper]
Histogram Sort with Sampling [SPAA 2019]
19-01
2019
[Paper]
[Paper]
Scalable Molecular Dynamics with NAMD on the Summit System [IBM Journal of Research and Development 2019]
18-05
2018
[Paper]
[Paper]
Accelerating scientific applications on heterogeneous systems with HybridOMP [VECPAR 2018]
18-04
2018
[Paper]
[Paper]
CharmPy: A Python Parallel Programming Model [Cluster 2018]
18-03
2018
[Paper]
[Paper]
Adaptive Methods for Irregular Parallel Discrete Event Simulation Workloads [ACM SIGSIM PADS 2018]
18-02
2018
[Paper]
[Paper]
Multi-level Load Balancing with an Integrated Runtime Approach [CCGrid 2018]
17-12
2017
[Paper]
[Paper]
NAMD: Scalable Molecular Dynamics Based on the Charm++ Parallel Runtime System [Book Chapter 2017]
17-10
2017
[Paper]
[Paper]
Optimizing Point-to-Point Communication between Adaptive MPI Endpoints in Shared Memory [ExaMPI 2017]
17-09
2017
[Paper]
[Paper]
Support for Power Efficient Proactive Cooling Mechanisms [HiPC 2017]
17-08
2017
[Paper]
[Paper]
Integrating OpenMP into the Charm++ Programming Model [ESPM2 2017]
17-07
2017
[Paper]
[Paper]
Visualizing, measuring, and tuning Adaptive MPI parameters [VPA 2017]
17-05
2017
[Paper]
[Paper]
Improving the memory access locality of hybrid MPI applications [EuroMPI 2017]
17-04
2017
[Paper]
[Paper]
A Memory Heterogeneity-Aware Runtime System for Bandwidth-Sensitive HPC Applications [IPDRM 2017]
17-03
2017
[Paper]
[Paper]
Massively Parallel Simulations of Spread of Infectious Diseases over Realistic Social Networks [CCGrid 2017]
17-02
2017
[Paper]
[Paper]
Automatic topology mapping of diverse large-scale parallel applications [ICS 2017]
16-19
2016
[Paper]
[Paper]
Handling Transient and Persistent Imbalance Together in Distributed and Shared Memory [PPL Technical Report 2016]
16-15
2016
[Paper]
[Paper]
FlipBack: Automatic Targeted Protection Against Silent Data Corruption [SC 2016]
16-14
2016
[Paper]
[Paper]
Runtime Coordinated Heterogeneous Tasks in Charm++ [ESPM2 2016]
16-13
2016
[Paper]
[Paper]
Neural Network-Based Task Scheduling with Preemptive Fan Control [E2SC 2016]
16-12
2016
[Paper]
[Paper]
Power, Reliability, Performance: One System to Rule Them All [Computer 2016]
16-11
2016
[Paper]
[Paper]
Evaluating HPC Networks via Simulation of Parallel Workloads [SC 2016]
16-10
2016
[Paper]
[Paper]
Energy-optimal Configuration Selection for Manycore Chips with Variation [IJHPCA 2016]
16-08
2016
[Paper]
[Paper]
Variation Among Processors Under Turbo Boost in HPC Systems [ICS 2016]
16-05
2016
[Paper]
[Paper]
OpenAtom: Scalable Ab-Initio Molecular Dynamics with Diverse Capability [ISC 2016]
16-03
2016
[Paper]
[Paper]
Mitigating Processor Variation through Dynamic Load Balancing [VarSys, IPDPS 2016]
16-01
2016
[Paper]
[Paper]
Towards PDES in a Message-Driven Paradigm: A Preliminary Case Study Using Charm++ [ACM SIGSIM PADS 2016]
15-16
2015
[Paper]
[Paper]
A Fault-Tolerance Protocol for Parallel Applications with Communication Imbalance [SBAC-PAD 2015]
15-14
2015
[Paper]
[Paper]
Preliminary Evaluation of a Parallel Trace Replay Tool for HPC Network Simulations [PADABS, EURO-PAR 2015]
15-12
2015
[Paper]
[Paper]
A Batch System with Efficient Adaptive Scheduling for Malleable and Evolving Applications [IPDPS 2015]
15-11
2015
[Paper]
[Paper]
Analyzing Energy-Time Tradeoff in Power Overprovisioned HPC Data Centers [HPPAC 2015]
15-10
2015
[Paper]
[Paper]
CAMEL: Collective-Aware Message Logging [TJS 2015]
15-06
2015
[Paper]
[Paper]
Scalable Asynchronous Contact Mechanics using Charm++ [IPDPS 2015]
15-03
2015
[Paper]
[Paper]
Identifying the Culprits behind Network Congestion [IPDPS 2015]
15-02
2015
[Paper]
[Paper]
Charm++ & MPI: Combining the Best of Both Worlds [IPDPS 2015]
15-01
2015
[Paper]
[Paper]
Energy-efficient Computing for HPC Workloads on Heterogeneous Manycore Chips [PMAM 2015]
14-41
2014
[Paper]
[Paper]
Applying Graph Partitioning Methods in Measurement-based Dynamic Load Balancing [CS Res. & Tech. Report 2014]
14-39
2014
[Paper]
[Paper]
Toward Exascale Resilience: 2014 update [Supercomputing Frontiers And Innovations 2014]
14-35
2014
[Paper]
[Paper]
Scheduling for HPC Systems with Process Variation Heterogeneity [PPL Technical Report 2014]
14-32
2014
[Paper]
[Paper]
Scaling the ISAM Land Surface Model Through Parallelization of Inter-Component Data Transfer [ICPP 2014]
14-30
2015
[Paper]
[Paper]
Adaptive Techniques for Clustered N-Body Cosmological Simulations [Computational Astrophysics and Cosmology 2015]
14-29
2014
[Paper]
[Paper]
Towards Realizing the Potential of Malleable Jobs [HiPC 2014]
14-28
2014
[Paper]
[Paper]
On Interoperation among User-driven and System-driven Parallel Languages [CS Res. & Tech. Report 2014]
14-27
2014
[Paper]
[Paper]
Power Management of Extreme-scale Networks with On/Off Links in Runtime Systems [TOPC 2014]
14-25
2014
[Paper]
[Paper]
Evaluating and Improving the Performance and Scheduling of HPC Applications in Cloud [IEEE TCC 2014]
14-24
2014
[Paper]
[Paper]
Optimizing Data Locality for Fork/Join Programs Using Constrained Work Stealing [SC 2014]
14-23
2014
[Paper]
[Paper]
Using an Adaptive HPC Runtime System to Reconfigure the Cache Hierarchy [SC 2014]
14-21
2014
[Paper]
[Paper]
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance [Cluster 2014]
14-20
2014
[Paper]
[Paper]
Using Migratable Objects to Enhance Fault Tolerance Schemes in Supercomputers [IEEE Transactions on Parallel and Distributed Systems 2014]
14-19
2014
[Paper]
[Paper]
Position Paper: Power-aware and Temperature Restrain Modeling for Maximizing Performance and Reliability [MODSIM 2014]
14-18
2014
[Paper]
[Paper]
TRAM: Optimizing Fine-grained Communication with Topological Routing and Aggregation of Messages [ICPP 2014]
14-17
2014
[Paper]
[Paper]
Mapping to Irregular Torus Topologies and Other Techniques for Petascale Biomolecular Simulation [SC 2014]
14-15
2014
[Paper]
[Paper]
Maximizing Throughput of Overprovisioned HPC Data Centers Under a Strict Power Budget [SC 2014]
14-14
2014
[Paper]
[Paper]
Optimizing the performance of parallel applications on a 5D torus via task mapping [HiPC 2014]
14-13
2014
[Paper]
[Paper]
Structure-Adaptive Parallel Solution of Sparse Triangular Linear Systems [ParCo 2014]
14-12
2014
[Paper]
[Paper]
PICS: A Performance-Analysis-Based Introspective Control System to Steer Parallel Applications [ROSS 2014]
14-07
2014
[Paper]
[Paper]
Parallel Programming with Migratable Objects: Charm++ in Practice [SC 2014]
14-04
2014
[Paper]
[Paper]
Maximizing Throughput on a Dragonfly Network [SC 2014]
14-02
2014
[Paper]
[Paper]
Energy Profile of Rollback-Recovery Strategies in High Performance Computing [ParCo 2014]
14-01
2014
[Paper]
[Paper]
Overcoming the Scalability Challenges of Epidemic Simulations on Blue Waters [IPDPS 2014]
13-60
2013
[Paper]
[Paper]
Position Paper: Actionable Performance Modeling for Future Supercomputers [MODSIM 2013]
13-51
2013
[Paper]
[Paper]
ACM SRC: Structure-Aware Parallel Algorithm for Solution of Sparse Triangular Linear Systems [SC 2013]
13-46
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 1: The Charm++ Programming Model [Book 2013]
13-45
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 2: Designing Charm++ Programs [Book 2013]
13-44
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 3: Tools for Debugging and Performance Analysis [Book 2013]
13-43
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 4: Scalable Molecular Dynamics with NAMD [Book 2013]
13-42
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 5: OpenAtom: Ab-initio Molecular Dynamics for Petascale Platforms [Book 2013]
13-41
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 6: N-body Simulations with ChaNGa [Book 2013]
13-36
2012
[Paper]
[Paper]
Controlling Concurrency and Expressing Synchronization in Charm++ Programs [Concurrent Objects and Beyond 2012]
13-33
2013
[Paper]
[Paper]
Thermal Aware Automated Load Balancing for HPC Applications [Cluster 2013]
13-30
2013
[Paper]
[Paper]
The Who, What, Why, and How of High Performance Computing in the Cloud [CloudCom 2013]
13-29
2013
[Paper]
[Paper]
Parallel Branch-and-Bound for Two-Stage Stochastic Integer Optimization (Best Paper Award) [HiPC 2013]
13-26
2013
[Paper]
[Paper]
A Distributed Dynamic Load Balancer for Iterative Applications [SC 2013]
13-25
2013
[Paper]
[Paper]
A ‘Cool’ Way of Improving the Reliability of HPC Machines [SC 2013]
13-24
2013
[Paper]
[Paper]
ACR: Automatic Checkpoint/Restart for Soft and Hard Error Protection [SC 2013]
13-22
2013
[Paper]
[Paper]
Position Paper: A Multi-resolution Emulation + Simulation Methodology [MODSIM 2013]
13-20
2013
[Paper]
[Paper]
Optimizing Power Allocation to CPU and Memory Subsystems in Overprovisioned HPC Systems [Cluster 2013]
13-19
2013
[Paper]
[Paper]
The Who, What, Why and How of High Performance Computing Applications in the Cloud [HPL 2013]
13-18
2013
[Paper]
[Paper]
Predicting Application Performance using Supervised Learning on Communication Features [SC 2013]
13-16
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach [Book 2013]
13-09
2013
[Paper]
[Paper]
Toward Runtime Power Management of Exascale Networks by On/Off Control of Links [HPPAC 2013]
13-08
2013
[Paper]
[Paper]
In Search of a Scalable, Parallel Branch-and-Bound for Two-Stage Stochastic Integer Optimization [PPL Technical Report 2013]
13-07
2013
[Paper]
[Paper]
Towards Efficient Mapping, Scheduling, and Execution of HPC Applications on Platforms in Cloud [IPDPS PhD Forum 2013]
13-05
2013
[Paper]
[Paper]
Improving HPC Application Performance in Cloud through Dynamic Load Balancing [CCGrid 2013]
13-04
2013
[Paper]
[Paper]
Steal Tree: Low-Overhead Tracing of Work Stealing Schedulers [PLDI 2013]
13-01
2013
[Paper]
[Paper]
HPC-Aware VM Placement in Infrastructure Clouds [IC2E 2013]
12-62
2012
[Paper]
[Paper]
Incorporating Dynamic Communication Patterns in a Static Dataflow Notation [DFM 2012]
12-50
2013
[Paper]
[Paper]
Acceleration of an Asynchronous Message Driven Programming Paradigm on IBM Blue Gene/Q [IPDPS 2013]
12-47
2012
[Paper]
[Paper]
Migratable Objects + Active Messages + Adaptive Runtime = Productivity + Performance: A Submission to the 2012 HPC Class II Challenge [SC 2012]
12-46
2013
[Paper]
[Paper]
Adoption Protocols for Fanout-Optimal Fault-Tolerant Termination Detection [PPoPP 2013]
12-42
2012
[Paper]
[Paper]
Structure-Adaptive Parallel Solution of Sparse Triangular Linear Systems [PPL Technical Report 2012]
12-39
2012
[Paper]
[Paper]
Parallelizing Information Set Generation for Game Tree Search Applications. [SBAC-PAD 2012]
12-38
2012
[Paper]
[Paper]
Optimizing VM Placement for HPC in the Cloud [WCS&OCS 2012]
12-37
2012
[Paper]
[Paper]
Assessing Energy Efficiency of Fault Tolerance Protocols for HPC Systems [SBAC-PAD 2012]
12-36
2012
[Paper]
[Paper]
Performance Optimization of a Parallel, Two Stage Stochastic Linear Program: The Military Aircraft Allocation Problem [ICPADS 2012]
12-35
2012
[Paper]
[Paper]
Scalable Algorithms for Distributed-Memory Adaptive Mesh Refinement [SBAC-PAD 2012]
12-33
2012
[Paper]
[Paper]
Optimizing Fine-grained Communication in a Biomolecular Simulation Application on Cray XK6 [SC 2012]
12-32
2012
[Paper]
[Paper]
Hiding Checkpoint Overhead in HPC Applications with a Semi-Blocking Algorithm [Cluster 2012]
12-31
2012
[Paper]
[Paper]
A Hierarchical Approach for Load Balancing on Parallel Multi-core Systems [ICPP 2012]
12-29
2012
[Paper]
[Paper]
Automated Load Balancing Invocation based on Application Characteristics [Cluster 2012]
12-28
2012
[Paper]
[Paper]
Efficient ‘Cool Down’ of Parallel Applications [PASA 2012]
12-27
2012
[Paper]
[Paper]
Cloud Friendly Load Balancing for HPC Applications: Preliminary Work [CloudTech-HPC 2012]
12-22
2012
[Paper]
[Paper]
Scalable Algorithms for Constructing Balanced Spanning Trees on System-ranked Process Groups [EuroMPI 2012]
12-21
2012
[Paper]
[Paper]
Collectives on Two-tier Direct Networks [EuroMPI 2012]
12-20
2012
[Paper]
[Paper]
‘Cool’ Load Balancing for High Performance Computing Data Centers [IEEE TC 2012]
12-19
2012
[Paper]
[Paper]
Short Paper: Exploring the Performance and Mapping of HPC Applications to Platforms in the Cloud [HPDC 2012]
12-14
2012
[Paper]
[Paper]
A Message-Logging Protocol for Multicore Systems [FTXS 2012]
12-12
2012
[Paper]
[Paper]
A Scalable Double In-memory Checkpoint and Restart Scheme towards Exascale [FTXS 2012]
12-11
2012
[Paper]
[Paper]
Work Stealing and Persistence-based Load Balancers for Iterative Overdecomposed Applications [HPDC 2012]
12-07
2012
[Paper]
[Paper]
Parallel Computing for DoD Airlift Allocation [PPL Technical Report 2012]
12-06
2012
[Paper]
[Paper]
Dynamic Scheduling for Work Agglomeration on Heterogeneous Clusters [Workshop on Multicore and GPU Programming Models, Languages and Compilers at IPDPS 2012]
12-04
2012
[Paper]
[Paper]
A Scalable Double In-memory Checkpoint and Restart Scheme towards Exascale [PPL Technical Report 2012]
11-58
2011
[Paper]
[Paper]
Detecting and Using Critical Paths at Runtime in Message Driven Parallel Programs [IJNC 2011]
11-54
2011
[Paper]
[Paper]
ACM SRC: Optimizing All-to-All Algorithm for PERCS Network Using Simulation [SC 2011]
11-51
2012
[Paper]
[Paper]
Mapping Dense LU Factorization on Multicore Supercomputer Nodes [IPDPS 2012]
11-50
2012
[Paper]
[Paper]
A uGNI-Based Asynchronous Message-Driven Runtime System for Cray Supercomputers with Gemini Interconnect [IPDPS 2012]
11-49
2011
[Paper]
[Paper]
Charm++ for Productivity and Performance: A Submission to the 2011 HPC Class II Challenge [SC 2011]
11-41
2011
[Paper]
[Paper]
Using Shared Arrays in Message-Driven Parallel Programs [ParCo 2011]
11-37
2011
[Paper]
[Paper]
Simulation-based Performance Analysis and Tuning for a Two-level Directly Connected System [ICPADS 2011]
11-34
2011
[Paper]
[Paper]
Exploring Partial Synchrony in an Asynchronous Environment Using Dense LU [PPL Technical Report 2011]
11-30
2011
[Paper]
[Paper]
Design and Analysis of a Message Logging Protocol for Fault Tolerant Multicore Systems [PPL Technical Report 2011]
11-28
2011
[Paper]
[Paper]
Improving Parallel System Performance with a NUMA-aware Load Balancer [CS Res. & Tech. Report 2011]
11-27
2011
[Paper]
[Paper]
Optimizations for Message Driven Applications on Multicore Architectures [HiPC 2011]
11-26
2011
[Paper]
[Paper]
Dynamic Load Balance for Optimized Message Logging in Fault Tolerant HPC Applications [Cluster 2011]
11-25
2011
[Paper]
[Paper]
ParSSSE: An Adaptive Parallel State Space Search Engine [PPL 2011]
11-23
2011
[Paper]
[Paper]
Automatic Handling of Global Variables for Multi-threaded MPI Programs [ICPADS 2011]
11-21
2011
[Paper]
[Paper]
Avoiding Hot-Spots on Two-Level Direct Networks [SC 2011]
11-18
2011
[Paper]
[Paper]
A ‘Cool’ Load Balancer for Parallel Applications [SC 2011]
11-17
2011
[Paper]
[Paper]
Enabling and Scaling Biomolecular Simulations of 100~Million Atoms on Petascale Machines with a Multicore-Optimized Message-Driven Runtime [SC 2011]
11-13
2011
[Paper]
[Paper]
Using Shared Arrays in Message-Driven Parallel Programs [HIPS 2011]
11-12
2011
[Paper]
[Paper]
Heuristic-Based Techniques for Mapping Irregular Communication Graphs to Mesh Topologies [ESCAPE 2011]
11-11
2011
[Paper]
[Paper]
A Multi-level Scalable Startup for Parallel Applications [ROSS 2011]
11-10
2011
[Paper]
[Paper]
Temperature Aware Load Balancing for Parallel Applications: Preliminary Work [HPPAC 2011]
11-09
2011
[Paper]
[Paper]
Charm++ [Encyclopedia of Parallel Computing 2011]
11-08
2011
[Paper]
[Paper]
Parallel Sorting [Encyclopedia of Parallel Computing 2011]
11-07
2011
[Paper]
[Paper]
Distributed Memory Load Balancing [Encyclopedia of Parallel Computing 2011]
11-06
2011
[Paper]
[Paper]
Parallel Combinatorial Search [Encyclopedia of Parallel Computing 2011]
11-05
2011
[Paper]
[Paper]
An Adaptive Framework for Large-scale State Space Search [LSPP 2011]
11-04
2011
[Paper]
[Paper]
Evaluation of Simple Causal Message Logging for Large-Scale Fault Tolerant HPC Systems [DPDNS 2011]
11-03
2011
[Paper]
[Paper]
Accelerator Support in the Charm++ Parallel Programming Model [Scientific Computing with Multicore and Accelerators 2011]
11-01
2011
[Paper]
[Paper]
Architectural Constraints to Attain 1 Exaflop/s on Three Scientific Application Classes [IPDPS 2011]
10-26
2011
[Paper]
[Paper]
A Comparative Analysis of Load Balancing Algorithms Applied to a Weather Forecast Model [SBAC-PAD 2011]
10-25
2011
[Paper]
[Paper]
NAnoscale Molecular Dynamics (NAMD) [Encyclopedia of Parallel Computing 2011]
10-23
2010
[Paper]
[Paper]
Debugging Parallel Applications via Provisional Execution [PPL Technical Report 2010]
10-21
2010
[Paper]
[Paper]
Optimizing an MPI Weather Forecasting Model via Processor Virtualization [HiPC 2010]
10-20
2010
[Paper]
[Paper]
Periodic Hierarchical Load Balancing for Large Supercomputers [IJHPCA 2010]
10-19
2010
[Paper]
[Paper]
A Study of Memory-Aware Scheduling in Message Driven Parallel Programs [HiPC 2010]
10-18
2010
[Paper]
[Paper]
Automated Mapping of Regular Communication Graphs on Mesh Interconnects [HiPC 2010]
10-16
2010
[Paper]
[Paper]
Scaling Hierarchical N-Body Simulations on GPU Clusters [SC 2010]
10-15
2010
[Paper]
[Paper]
Simulating Large Scale Parallel Applications using Statistical Models for Sequential Execution Blocks [ICPADS 2010]
10-14
2010
[Paper]
[Paper]
Automatic MPI to AMPI Program Transformation using Photran [PROPER 2010]
10-13
2010
[Paper]
[Paper]
Optimizing a Parallel Runtime System for Multicore Clusters: A Case Study [TeraGrid 2010]
10-12
2010
[Paper]
[Paper]
Robust Non-Intrusive Record-Replay with Processor Extraction [PADTAD 2010]
10-11
2010
[Paper]
[Paper]
Debugging Large Scale Applications in a Virtualized Environment [LCPC 2010]
10-10
2010
[Paper]
[Paper]
Static Macro Data Flow: Compiling Global Control into Local Control [HIPS 2010]
10-09
2010
[Paper]
[Paper]
Automatic MPI to AMPI Program Transformation [Charm++ Workshop 2010]
10-08
2010
[Paper]
[Paper]
Hierarchical Load Balancing for Charm++ Applications on Large Supercomputers [P2S2 2010]
10-07
2010
[Paper]
[Paper]
Automated Mapping of Structured Communication Graphs onto Mesh Interconnects [CS Res. & Tech. Report 2010]
10-06
2009
[Paper]
[Paper]
Charm++ and AMPI: Adaptive Runtime Strategies via Migratable Objects [Advanced Computational Infrastructures for Parallel and Distributed Applications 2009]
10-05
2010
[Paper]
[Paper]
A Study of Memory-Aware Scheduling in Message Driven Parallel Programs [PPL Technical Report 2010]
10-04
2010
[Paper]
[Paper]
Optimizing Communication for Charm++ Applications by Reducing Network Contention [Concurrency and Computation: Practice and Experience 2010]
10-03
2010
[Paper]
[Paper]
Understanding Application Performance via Micro-Benchmarks on Three Large Supercomputers: Intrepid, Ranger and Jaguar [IJHPCA 2010]
10-02
2010
[Paper]
[Paper]
Team-based Message Logging: Preliminary Results [Resilience 2010]
10-01
2010
[Paper]
[Paper]
Detecting and Using Critical Paths at Runtime in Message Driven Parallel Programs [APDCM 2010]
09-30
2009
[Paper]
[Paper]
Patterns for Overlapping Communication and Computation [ParaPLoP 2009]
09-14
2009
[Paper]
[Paper]
PGAS in the Message-Driven Execution Model [APGAS 2009]
09-12
2009
[Paper]
[Paper]
Early Application Development/Tuning and Application Characterization/ Segmentation [IJHPCA 2009]
09-11
2009
[Paper]
[Paper]
Programming Models at Exascale: Adaptive Runtime Systems, Incomplete Simple Languages, and Interoperability [IJHPCA 2009]
09-10
2010
[Paper]
[Paper]
Highly Scalable Parallel Sorting [IPDPS 2010]
09-09
2009
[Paper]
[Paper]
Towards a Framework for Abstracting Accelerators in Parallel Applications: Experience with Cell [SC 2009]
09-08
2009
[Paper]
[Paper]
Continuous Performance Monitoring for Large-Scale Parallel Applications [HiPC 2009]
09-07
2009
[Paper]
[Paper]
Quantifying Network Contention on Large Parallel Machines [PPL 2009]
09-06
2009
[Paper]
[Paper]
Flexible Hardware Mapping for Finite Element Simulations on Hybrid CPU / GPU Clusters [SAAHPC 2009]
09-05
2009
[Paper]
[Paper]
Integrated Performance Views in Charm ++: Projections Meets TAU [ICPP 2009]
09-04
2009
[Paper]
[Paper]
A Pattern Language for Topology Aware Mapping [ParaPLoP 2009]
09-03
2009
[Paper]
[Paper]
Scalable Interaction with Parallel Applications [TeraGrid 2009]
09-02
2009
[Paper]
[Paper]
Dynamic Topology Aware Load Balancing Algorithms for Molecular Dynamics Applications [ICS 2009]
09-01
2009
[Paper]
[Paper]
An Evaluative Study on the Effect of Contention on Message Latencies in Large Supercomputers [LSPP 2009]
08-15
2009
[Paper]
[Paper]
Parallel Simulations of Dynamic Fracture Using Extrinsic Cohesive Elements [J. Sci. Comp. 2009]
08-14
2008
[Paper]
[Paper]
Control Points for Adaptive Parallel Performance Tuning [PPL Technical Report 2008]
08-13
2008
[Paper]
[Paper]
A Case Study in Tightly Coupled Multi-paradigm Parallel Programming [LCPC 2008]
08-11
2009
[Paper]
[Paper]
CkDirect: Unsynchronized One-Sided Communication in a Message-Driven Paradigm [P2S2 2009]
08-10
2009
[Paper]
[Paper]
A Case Study of Communication Optimizations on 3D Mesh Interconnects [Euro-Par 2009]
08-09
2008
[Paper]
[Paper]
Some Essential Techniques for Developing Efficient Petascale Applications [SciDAC 2008]
08-08
2009
[Paper]
[Paper]
Dynamic High-Level Scripting in Parallel Applications [IPDPS 2009]
08-07
2008
[Paper]
[Paper]
Benefits of Topology Aware Mapping for Mesh Interconnects [PPL 2008]
08-06
2008
[Paper]
[Paper]
Memory Tagging in Charm++ [PADTAD 2008]
08-05
2008
[Paper]
[Paper]
Towards Scalable Performance Analysis and Visualization through Data Reduction [HIPS 2008]
08-04
2008
[Paper]
[Paper]
NoiseMiner: An Algorithm for Scalable Automatic Computational Noise and Software Interference Detection [HIPS 2008]
08-03
2008
[Paper]
[Paper]
Massively Parallel Cosmological Simulations with ChaNGa [IPDPS 2008]
08-02
2008
[Paper]
[Paper]
Application-specific Topology-aware Mapping for Three Dimensional Topologies [LSPP 2008]
08-01
2008
[Paper]
[Paper]
Overcoming Scaling Challenges in Biomolecular Simulations across Multiple Platforms [IPDPS 2008]
07-11
2007
[Paper]
[Paper]
Parallel Prim’s algorithm on dense graphs with a novel extension [PPL Technical Report 2007]
07-10
2007
[Paper]
[Paper]
NAMD: A Portable and Highly Scalable Program for Biomolecular Simulations [CS Res. & Tech. Report 2007]
07-09
2007
[Paper]
[Paper]
Towards Petascale Cosmological Simulations with ChaNGa [PPL Technical Report 2007]
07-08
2007
[Paper]
[Paper]
Supporting Adaptivity in MPI for Dynamic Parallel Applications [PPL Technical Report 2007]
07-07
2007
[Paper]
[Paper]
Parallel Simulations of Dynamic Fracture Using Extrinsic Cohesive Elements [PPL Technical Report 2007]
07-06
2007
[Paper]
[Paper]
Scalable Techniques for Performance Analysis [CS Res. & Tech. Report 2007]
07-05
2008
[Paper]
[Paper]
Biomolecular Modeling in the Era of Petascale Computing [Petascale Computing: Algorithms and Applications 2008]
07-04
2007
[Paper]
[Paper]
Programming Petascale Applications with Charm++ and AMPI [Petascale Computing: Algorithms and Applications 2007]
07-03
2007
[Paper]
[Paper]
Fine Grained Parallelization of the Car-Parrinello ab initio MD Method on Blue Gene/L [IBM Journal of Research and Development 2007]
07-02
2007
[Paper]
[Paper]
Scalable Molecular Dynamics with NAMD on Blue Gene/L [IBM Journal of Research and Development 2007]
07-01
2007
[Paper]
[Paper]
Optimizing Distributed Application Performance Using Dynamic Grid Topology-Aware Load Balancing [IPDPS 2007]
06-18
2007
[Paper]
[Paper]
Charisma: Orchestrating Migratable Parallel Objects [HPDC 2007]
06-15
2006
[Paper]
[Paper]
Parallel Adaptive Simulations of Dynamic Fracture Events [Engineering with Computers 2006]
06-14
2006
[Paper]
[Paper]
Charm++, Offload API, and the Cell Processor [PMUP 2006]
06-13
2006
[Paper]
[Paper]
Quantifying the Interference Caused by Subnormal Floating-Point Values [OSIHPA 2006]
06-12
2007
[Paper]
[Paper]
A Fault Tolerance Protocol with Fast Fault Recovery [IPDPS 2007]
06-11
2006
[Paper]
[Paper]
Proactive Fault Tolerance in MPI Applications via Task Migration [HiPC 2006]
06-08
2006
[Paper]
[Paper]
Automatic Dynamic Load Balancing for a Crack Propagation Application [PPL Technical Report 2006]
06-06
2006
[Paper]
[Paper]
Run-time Support for Controlling Communication-Induced Memory Fluctuation [PPL Technical Report 2006]
06-05
2006
[Paper]
[Paper]
Multiple Flows of Control in Migratable Parallel Programs [HPSEC 2006]
06-04
2006
[Paper]
[Paper]
HPC-Colony: Services and Interfaces for Very Large Systems [OSR Special Issue on HEC OS/Runtimes 2006]
06-03
2006
[Paper]
[Paper]
Performance Evaluation of Automatic Checkpoint-based Fault Tolerance for AMPI and Charm++ [Operating and Runtime Systems for High-end Computing Systems 2006]
06-02
2006
[Paper]
[Paper]
Support for Adaptivity in ARMCI Using Migratable Objects [POHLL 2006]
06-01
2006
[Paper]
[Paper]
Scalable Cosmological Simulations on Parallel Machines [VECPAR 2006]
05-24
2005
[Paper]
[Paper]
Biomolecular Modeling using Parallel Supercomputers [Handbook of Computational Molecular Biology 2005]
05-23
2005
[Paper]
[Paper]
Scalable Molecular Dynamics with NAMD [Journal of Computational Chemistry 2005]
05-22
2005
[Paper]
[Paper]
Parallelization of Level Set Methods for Solving Solidification Problems [PPL Technical Report 2005]
05-21
2005
[Paper]
[Paper]
The Nonsingularity of Sparse Approximate Inverse Preconditioning and Its Performance Based on Processor Virtualization [PPL Technical Report 2005]
05-20
2005
[Paper]
[Paper]
A Parallel Multigrid Solver Based on ProcessorVirtualization Techniques [PPL Technical Report 2005]
05-19
2005
[Paper]
[Paper]
Performance Visualization and Analysis of Parallel Discrete Event Simulations with Projections [PPL Technical Report 2005]
05-18
2006
[Paper]
[Paper]
Topology-Aware Task Mapping for Reducing Communication Contention on Large Parallel Machines [IPDPS 2006]
05-15
2005
[Paper]
[Paper]
Scalable, Fine Grain, Parallelization of the Car-Parrinello ab initio Molecular Dynamics Method [PPL Technical Report 2005]
05-14
2006
[Paper]
[Paper]
ParFUM: A Parallel Framework for Unstructured Meshes for Scalable Dynamic Physics Applications [Engineering with Computers 2006]
05-13
2006
[Paper]
[Paper]
Achieving Strong Scaling with NAMD on Blue Gene/L [IPDPS 2006]
05-12
2005
[Paper]
[Paper]
Performance Degradation in the Presence of Subnormal Floating-Point Values [OSIHPA 2005]
05-11
2005
[Paper]
[Paper]
Scaling an Optimistic Parallel Simulation of Large-scale Interconnection Networks [WSC 2005]
05-04
2006
[Paper]
[Paper]
Performance Evaluation of Adaptive MPI [PPoPP 2006]
05-03
2005
[Paper]
[Paper]
Performance Prediction using Simulation of Large-scale InterconnectionNetworks in POSE [PADS 2005]
05-02
2005
[Paper]
[Paper]
Architecture for supporting Hardware Collectives in Output-Queued High-Radix Routers [HiPC 2005]
04-17
2004
[Paper]
[Paper]
Scalable Fine-Grained Parallelization of Plane-Wave-Based ab initio Molecular Dynamics for Large Supercomputers [Journal of Computational Chemistry 2004]
04-16
2004
[Paper]
[Paper]
Performance and Modularity Benefits of Message-Driven Execution [Journal of Parallel and Distributed Computing 2004]
04-15
2005
[Paper]
[Paper]
Using Message-Driven Objects to Mask Latency in Grid Computing Applications [IPDPS 2005]
04-14
2005
[Paper]
[Paper]
Proactive Fault Tolerance in Large Systems [HPCRI 2005]
04-13
2004
[Paper]
[Paper]
An Orchestration Language for Parallel Objects [LCR 2004]
04-12
2005
[Paper]
[Paper]
Simulation-Based Performance Prediction for Large Parallel Machines [IJPP 2005]
04-10
2004
[Paper]
[Paper]
MSA: Multiphase Specifically Shared Arrays [LCPC 2004]
04-09
2004
[Paper]
[Paper]
Faucets: Efficient Resource Allocation on the Computational Grid [ICPP 2004]
04-06
2004
[Paper]
[Paper]
FTC-Charm++: An In-Memory Checkpoint-Based Fault Tolerant Runtime for Charm++ and MPI [Cluster 2004]
04-05
2004
[Paper]
[Paper]
Scaling Applications to Massively Parallel Machines Using Projections Performance Analysis Tool [FGCS 2004]
04-04
2004
[Paper]
[Paper]
Debugging Support for Charm++ [PADTAD 2004]
04-03
2004
[Paper]
[Paper]
A Fault Tolerant Protocol for Massively Parallel Systems [FTPDS 2004]
04-02
2004
[Paper]
[Paper]
Performance Modeling and Programming Environments for Petaflops Computers and the Blue Gene Machine [NSFNGS 2004]
04-01
2004
[Paper]
[Paper]
POSE: Getting Over Grainsize in Parallel Discrete Event Simulation [ICPP 2004]
03-16
2004
[Paper]
[Paper]
Performance and Productivity in Parallel Programming via Processor Virtualization [PPHEC 2004]
03-15
2003
[Paper]
[Paper]
Opportunities and Challenges of Modern Communication Architectures:Case Study with QsNet [CAC Workshop at IPDPS 2003]
03-11
2003
[Paper]
[Paper]
Scaling Collective Multicast on Fat-tree Networks [ICPADS 2003]
03-10
2003
[Paper]
[Paper]
Supporting Dynamic Parallel Object Arrays [Concurrency and Computation: Practice and Experience 2003]
03-07
2003
[Paper]
[Paper]
Adaptive MPI [LCPC 2003]
03-06
2003
[Paper]
[Paper]
Scalable Parallelization of Ab Initio Molecular Dynamics [PPL Technical Report 2003]
03-05
2004
[Paper]
[Paper]
BigSim: A Parallel Simulator for Performance Prediction of Extremely Large Parallel Machines [IPDPS 2004]
03-04
2003
[Paper]
[Paper]
Scaling Collective Multicast on High Performance Clusters [PPL Technical Report 2003]
03-03
2003
[Paper]
[Paper]
Scaling Molecular Dynamics to 3000 Processors with Projections: A Performance Analysis Case Study [Workshop on Terascale Performance Analysis at ICCS 2003]
03-02
2003
[Paper]
[Paper]
Jade: A Parallel Message-Driven Java [Workshop on Java in Computational Science at ICCS 2003]
03-01
2003
[Paper]
[Paper]
Faucets: Efficient Resource Allocation on the Computational Grid [PPL Technical Report 2003]
02-10
2003
[Paper]
[Paper]
A Framework for Collective Personalized Communication [IPDPS 2003]
02-09
2002
[Paper]
[Paper]
The Virtualization Approach to Parallel Programming: Runtime Optimizations and the State of the Art [LACSI 2002]
02-07
2002
[Paper]
[Paper]
NAMD: Biomolecular Simulation on Thousands of Processors [SC 2002]
02-06
2002
[Paper]
[Paper]
A Voxel-Based Parallel Collision Detection Algorithm [ICS 2002]
02-05
2002
[Paper]
[Paper]
Adaptive MPI [PPL Technical Report 2002]
02-04
2002
[Paper]
[Paper]
NAMD: Biomolecular Simulation on Thousands of Processors [Scaling to New Heights Workshop at Pittsburgh Supercomputing Center 2002]
02-03
2002
[Paper]
[Paper]
A Parallel-Object Programming Model for Petaflops Machines and Blue Gene/Cyclops [NSFNGS 2002]
02-01
2002
[Paper]
[Paper]
A Malleable-Job System for Timeshared Parallel Machines [CCGrid 2002]
01-04
2001
[Paper]
[Paper]
Emulating Petaflops Machines and Blue Gene [IPDPS 2001]
01-03
2001
[Paper]
[Paper]
An Interface Model for Parallel Components [LCPC 2001]
01-02
2001
[Paper]
[Paper]
Improving Paging Performace With Object Prefetching [PPL Technical Report 2001]
01-01
2001
[Paper]
[Paper]
Supporting Dynamic Parallel Object Arrays [JGI 2001]
00-06
2000
[Paper]
[Paper]
Scalable Molecular Dynamics for Large Biomolecular Systems [SC 2000]
00-05
2000
[Paper]
[Paper]
Run-time Support for Adaptive Load Balancing [RTSPP 2000]
00-04
2000
[Paper]
[Paper]
A New Approach to Software Integration Frameworks for Multi-Physics Simulation Codes [IFIP Conference on the Architecture of Scientific Software 2000]
00-03
2001
[Paper]
[Paper]
Object-Based Adaptive Load Balancing for MPI Programs [ICCS 2001]
00-02
2000
[Paper]
[Paper]
An Adaptive Job Scheduler for Timeshared Parallel Machines [PPL Technical Report 2000]
00-01
2000
[Paper]
[Paper]
A Parallel Framework for Explicit FEM [HiPC 2000]
99-07
1999
[Paper]
[Paper]
BioCoRE: A Collaboratory for Structural Biology [SCS International Conference on Web-Based Modeling and Simulation 1999]
99-06
1999
[Paper]
[Paper]
Branch and Bound Based Load Balancing for Parallel Applications [LNCS 1999]
99-05
1999
[Paper]
[Paper]
Web-based Interaction and Monitoring for Parallel Programs (ViaConspector) [PPL Technical Report 1999]
99-04
1999
[Paper]
[Paper]
Multilingual Debugging Support for Data-Driven and Thread-Based Parallel Languages [LCPC 1999]
99-03
2000
[Paper]
[Paper]
Handling Application-Induced Load Imbalance using Parallel Objects [Parallel and Distributed Computing for Symbolic and Irregular Applications 2000]
99-02
1999
[Paper]
[Paper]
Adapting to Load on Workstation Clusters [ Frontiers of Massively Parallel Computation 1999]
99-01
2000
[Paper]
[Paper]
Application Performance of a Linux Cluster using Converse [RTSPP 2000]
98-10
1999
[Paper]
[Paper]
Algorithmic Challenges in Computational Molecular Biophysics [Journal of Computational Physics 1999]
98-09
1998
[Paper]
[Paper]
Programming Languages for CSE: The State of the Art [IEEE Computational Science and Engineering 1998]
98-08
1998
[Paper]
[Paper]
NAMD: A Case Study in Multilingual Parallel Programming [LCPC 1998]
98-07
1998
[Paper]
[Paper]
Static Networks: A Powerful and Elegant Extension to Concurrent Object-Oriented Languages [LNCS 1998]
98-06
1998
[Paper]
[Paper]
Computational Molecular Biophysics Today: A Confluence of Methodological Advances and Complex Biomolecular Applications [Journal of Computational Physics 1998]
98-05
1998
[Paper]
[Paper]
Avoiding Algorithmic Obfuscation in a Message-Driven Parallel MD Code [LNCS 1998]
98-04
1998
[Paper]
[Paper]
Flexibility and Interoperability in a Parallel Molecular Dynamics Code [Object Oriented Methods for Inter-operable Scientific and Engineering Computing 1998]
98-03
1998
[Paper]
[Paper]
NAMD2: Greater Scalability for Parallel Molecular Dynamics [Journal of Computational Physics 1998]
98-02
1998
[Paper]
[Paper]
Load Balancing in Parallel Molecular Dynamics [International Symposium on Solving Irregularly Structured Problems in Parallel 1998]
98-01
1998
[Paper]
[Paper]
Multiparadigm, Multilingual Interoperability: Experience with Converse [RTSPP 1998]
97-03
1997
[Paper]
[Paper]
NAMD: A Case Study in Multilingual Parallel Programming [LCPC 1997]
97-02
1997
[Paper]
[Paper]
Design and Implementation of Parallel Java with Global Object Space [CPDPTA 1997]
96-15
1996
[Paper]
[Paper]
Simulating Message Driven Programs [ICPP 1996]
96-14
1996
[Paper]
[Paper]
Object-Oriented Implementation of the NAS Parallel Benchmarks using Charm++ [PPL Technical Report 1996]
96-12
1996
[Paper]
[Paper]
Towards Automatic Peformance Analysis [ICPP 1996]
96-11
1996
[Paper]
[Paper]
Charm++: Parallel Programming with Message-Driven Objects [Book Chapter 1996]
96-10
1996
[Paper]
[Paper]
Structured Dagger: A Coordination Language for Message-Driven Programming [Euro-Par 1996]
96-09
1995
[Paper]
[Paper]
Threads for Interoperable Parallel Programming [LCPC 1995]
96-08
1996
[Paper]
[Paper]
Automating Parallel Runtime Optimizations Using Post-Mortem Analysis [ICS 1996]
96-07
1996
[Paper]
[Paper]
Automating Runtime Optimizations for Load Balancing in Irregular Problems [CPDPTA 1996]
96-06
1996
[Paper]
[Paper]
A Parallel Array Abstraction for Data-Driven Objects [POOMA 1996]
96-05
1996
[Paper]
[Paper]
MICE: A Prototype MPI Implementation in Converse Environment [MPI Developers Conference 1996]
96-04
1996
[Paper]
[Paper]
NAMD - a Parallel, Object-Oriented Molecular Dynamics Program [International Journal Supercomputing Applications and High Performance Computing 1996]
96-03
1996
[Paper]
[Paper]
Converse : An Interoperable Framework for Parallel Programming [IPPS 1996]
96-02
1996
[Paper]
[Paper]
Converse : An Interoperable Framework for Parallel Programming [IPPS 1996]
96-01
1996
[Paper]
[Paper]
Converse : An Interoperable Framework for Parallel Programming [IPPS 1996]
95-16
1995
[Paper]
[Paper]
Parallel Import Report [PPL Technical Report 1995]
95-15
1995
[Paper]
[Paper]
Agents: an Undistorted Representation of Problem Structure [LCPC 1995]
95-13
1995
[Paper]
[Paper]
A Parallel Adaptive Fast Multipole algorithm for N-body problems [ICPP 1995]
95-11
2005
[Paper]
[Paper]
Efficient, Language-Based Checkpointing for Massively Parallel Programs [PPL Technical Report 2005]
95-07
1995
[Paper]
[Paper]
Modularity, Reuse, and Efficiency with Message-Driven Libraries [PPSC 1995]
95-06
1994
[Paper]
[Paper]
Efficient Implementation of High Performance Fortran via Adaptive Scheduling -- An Overview [IWPP 1994]
95-05
1995
[Paper]
[Paper]
Efficient Parallel Graph Coloring with Prioritization [LNCS 1995]
95-03
1995
[Paper]
[Paper]
The Charm Parallel Programming Language and System:Part II - The Runtime System [PPL Technical Report 1995]
95-02
1994
[Paper]
[Paper]
The Charm Parallel Programming Language and System:Part I --- Description of Language Features [PPL Technical Report 1994]
95-01
1995
[Paper]
[Paper]
MDScope - A visual Computing Environment for Structural Biology [Computer Physics Communications 1995]
94-05
1994
[Paper]
[Paper]
Efficient Implementation of High Performance Fortran via Adaptive Scheduling -- An Overview [IWPP 1994]
94-04
1994
[Paper]
[Paper]
Application-Oriented and Computer-Science-Centered HPCC Research [HPCC Workshop 1994]
94-03
1994
[Paper]
[Paper]
Dagger: Combining the Benefits of Synchronous and Asynchronous Communication Styles [IPPS 1994]
94-02
1994
[Paper]
[Paper]
Modeling Biomolecules: Larger Scales, Longer Durations [IEEECSE 1994]
94-01
1994
[Paper]
[Paper]
A Framework for Intelligent Performance Feedback [PPL Technical Report 1994]
93-16
1992
[Paper]
[Paper]
Prioritization in Parallel Computing (extended abstract) [Parallel Symbolic Computing Workshop 1992]
93-15
1993
[Paper]
[Paper]
A Portable Software Support System for Irregular Computations [PPL Technical Report 1993]
93-14
1993
[Paper]
[Paper]
Parallel Programming with CHARM: An Overview [PPL Technical Report 1993]
93-13
1993
[Paper]
[Paper]
A Load Balancing Strategy For Prioritized Execution of Tasks [International Symposium on Parallel Processing 1993]
93-12
1993
[Paper]
[Paper]
Medium Grained Execution in Concurrent Object Oriented Systems [Workshop on Efficient Implementation of Concurrent Object Oriented Languages at OOPSLA 1993]
93-11
1993
[Paper]
[Paper]
A Dynamic and Adaptive Quiescence Detection Algorithm [PPL Technical Report 1993]
93-10
1993
[Paper]
[Paper]
Tolerating Latency with Dagger [ISCIS 1993]
93-09
1996
[Paper]
[Paper]
Simulating Message Driven Programs [ICPP 1996]
93-08
1993
[Paper]
[Paper]
Performance Benefits of Message Driven Executions [Intel Supercomputer User's Group 1993]
93-07
1993
[Paper]
[Paper]
Loop Transformation for Prolog Programs [LNCS 1993]
93-06
1993
[Paper]
[Paper]
Prioritization in Parallel Symbolic Computing [LNCS 1993]
93-04
1993
[Paper]
[Paper]
Information Sharing Mechanisms in Parallel Programs [IPPS 1993]
93-03
1993
[Paper]
[Paper]
Dagger: Combining the Benefits of Synchronous and Asynchronous Communication Styles [PPL Technical Report 1993]
93-02
1993
[Paper]
[Paper]
CHARM++ : A Portable Concurrent Object Oriented System Based On C++ [OOPSLA 1993]
93-01
1993
[Paper]
[Paper]
A Comparison Based Parallel Sorting Algorithm [ICPP 1993]
92-10
1992
[Paper]
[Paper]
Dynamic Adaptive Scheduling in an Implementation of a Data Parallel Language [PPL Technical Report 1992]
92-09
1992
[Paper]
[Paper]
The Reduce-OR-Process Model for Parallel Logic Programming on Nonshared Memory Machines [Implementations of Distributed Prolog 1992]
92-07
1992
[Paper]
[Paper]
A Join Algorithm for Combining and Parallel Solutions in AND/OR Parallel Systems [IJPP 1992]
92-05
1992
[Paper]
[Paper]
A Load Balancing Strategy For Prioritized Execution of Tasks [Workshop on Dynamic Object Placement and Load Balancing at ECOOP 1992]
92-04
1992
[Paper]
[Paper]
Unsteady Fluid Flow Calculations Using a Machine Independent ParallelProgramming Environment [ParCFD 1992]
92-03
1992
[Paper]
[Paper]
Projections: a Preliminary Performance Tool for Charm [Parallel Systems Fair 1992]
92-02
1989
[Paper]
[Paper]
Parallel Problem Solving [Parallel Algorithms for Machine Intelligence and Pattern Recognition 1989]
92-01
1992
[Paper]
[Paper]
Estimating the Inherent Parallelism in Prolog Programs [International Conference on Fifth Generation Computer Systems 1992]
91-09
1991
[Paper]
[Paper]
Machine Independent AND and OR Parallel Execution of Logic Programs: Part I and Part II [IEEE Transactions on Parallel and Distributed Systems 1991]
91-08
1991
[Paper]
[Paper]
Supporting Machine Independent Parallel Programming on Diverse Architectures [ICPP 1991]
91-07
1991
[Paper]
[Paper]
The REDUCE OR Process Model for Parallel Execution of Logic Programs [Journal of Logic Programming 1991]
91-06
1994
[Paper]
[Paper]
Machine Independent AND and OR Parallel Execution of Logic Programs: Part II - Compiled Execution [IEEE Transactions on Parallel and Distributed Systems 1994]
91-05
1994
[Paper]
[Paper]
Machine Independent AND and OR Parallel Execution of Logic Programs: Part I - the Binding Environment [IEEE Transactions on Parallel and Distributed Systems 1994]
91-04
1991
[Paper]
[Paper]
Fortran-Style Transformations for Functional Programs (Extended Abstract) [ICPP 1991]
91-03
1991
[Paper]
[Paper]
High Level Support for Divide-and-Conquer Parallelism [SC 1991]
91-02
1991
[Paper]
[Paper]
Implementing a Parallel Prolog Interpreter on Multiprocessors [IPPS 1991]
91-01
1991
[Paper]
[Paper]
Efficient Parallel Execution of IDA on Shared and Distributed Memory Multiprocessors [DMCC 1991]
90-09
1990
[Paper]
[Paper]
Parallel State-space Search for a First Solution with Consistent Linear Speedups [IJPP 1990]
90-08
1990
[Paper]
[Paper]
Chare Kernel - A Runtime Support System for Parallel Computations [Journal of Parallel and Distributed Computing 1990]
90-07
1990
[Paper]
[Paper]
An Almost Perfect Heuristic for the N-queens Problem [Information Processing Letters 1990]
90-04
1990
[Paper]
[Paper]
Joining AND-Parallel Solutions in AND/OR Parallel Systems [NACLP 1990 1990]
90-03
1990
[Paper]
[Paper]
The Chare Kernel Parallel Programming Language and System [ICPP 1990]
90-02
1990
[Paper]
[Paper]
Consistent Linear Speedups for a First Solution in Parallel State-Space Search [AAAI 1990]
90-01
1990
[Paper]
[Paper]
A Chare Kernel Implementation of a Parallel Prolog Compiler [PPoPP 1990]
89-09
1989
[Paper]
[Paper]
An Abstract Machine for the Reduce or Process Model for Parallel Prolog [Knowledge Based Computer Systems 1989]
89-08
1989
[Paper]
[Paper]
A Dynamic Scheduling Strategy for the Chare Kernel System [SC 1989]
89-07
1989
[Paper]
[Paper]
Compiled Execution of the Reduce-Or Process Model on MultiProcessors [NACLP 1990 1989]
89-06
1989
[Paper]
[Paper]
Obtaining First Solutions Fast in Parallel Problem Solving [NACLP 1990 1989]
89-05
1989
[Paper]
[Paper]
The Chare Kernel Base Language: Preliminary Performance [ICPP 1989]
89-04
1989
[Paper]
[Paper]
A Specialized Expert System for Judicial Decision Support [ICAIL 1989]
89-03
1989
[Paper]
[Paper]
A Brief Perspective on Parallel Programming [TENCON 1989]
89-02
1989
[Paper]
[Paper]
Parallel Prolog on Intel's iPSC/2 [Hypercube Concurrent Computers and Applications 1989]
89-01
1989
[Paper]
[Paper]
The Mesh Superceded? [CSC 1989]
88-08
1988
[Paper]
[Paper]
OR Parallel Execution of Prolog Programs with Side Effects [TJS 1988]
88-07
1988
[Paper]
[Paper]
The Chare Kernel Language for Parallel Programming: A perspective [PPL Technical Report 1988]
88-06
1988
[Paper]
[Paper]
A Tree Representation for Parallel Problem Solving [AAAI 1988]
88-05
1988
[Paper]
[Paper]
A Memory Independent Binding Environment for AND and OR Parallel Execution of Logic Programs [International Conference on Logic Programming 1988]
88-04
1988
[Paper]
[Paper]
Comparing the Performance of Two Dynamic Load Distribution Methods [ICPP 1988]
88-03
1988
[Paper]
[Paper]
Prolog Research at University of Illinois [COMPCON 1988]
88-02
1988
[Paper]
[Paper]
D-Trees: A Class of Dense Regular Interconnection Topologies [ Frontiers of Massively Parallel Computation 1988]
87-02
1987
[Paper]
[Paper]
Parallel Execution of Logic Programs: the REDUCE-OR Process Model [International Conference on Logic Programming 1987]
87-01
1987
[Paper]
[Paper]
Completeness and Full Parallelism of Parallel Logic Programming Schemes [Symposium on Logic Programming 1987]
86-01
1986
[Paper]
[Paper]
Optimal Communication Neighborhoods [ICPP 1986]
85-01
1985
[Paper]
[Paper]
Lattice-Mesh: a Multi-Bus Topology [ICPP 1985]
84-01
1984
[Paper]
[Paper]
A Class of Architectures for a Prolog Machine [International Conference on Logic Programming 1984]
Talks/Posters
21-02
2021
[Poster]
[Poster]
CharminG: A Scalable GPU-resident Runtime System [HPDC 2021]
17-11
2017
[Poster]
[Poster]
ACM SRC: Runtime Support for Concurrent Execution of Overdecomposed Heterogeneous Tasks [SC 2017]
17-06
2017
[Poster]
[Poster]
Adaptive MPI: Dynamic Runtime Support for MPI Applications [EuroMPI 2017]
17-01
2017
[Poster]
[Poster]
Poster: Automated Load Balancer Selection Based on Application Characteristics [PPoPP 2017]
{kind=link}
{kind=link}
16-21
2016
[Poster]
[Poster]
ACM SRC: Mapping Applications on Irregular Allocations [SC 2016]
{kind=link}
16-16
2016
[Talk]
[Talk]
Optimizing Molecular Dynamics and Stencil mini-applications for Intel’s Knights Landing [IXPUG SC BOF 2016]
15-21
2015
[Talk]
[Talk]
Charm++ Motivations and Basic Ideas [ATPESC 2015]
15-20
2015
[Talk]
[Talk]
Charm++ Overview and suggestions for collaborations [JLESC 2015]
15-13
2015
[Talk]
[Talk]
Analyzing Energy-Time Tradeoff in Power Overprovisioned HPC Data Centers [HPPAC 2015]
15-09
2015
[Talk]
[Talk]
Energy-efficient Computing for HPC Workloads on Heterogeneous Manycore Chips [PMAM 2015]
14-49
2014
[Talk]
[Talk]
Adaptive runtime systems for computational chemistry [ACS 2014]
14-47
2014
[Talk]
[Talk]
Charm++ [ATPESC 2014]
14-45
2014
[Talk]
[Talk]
Temperature, Power and Energy: How an Adaptive Runtime can optimize them [JLESC 2014]
14-43
2014
[Talk]
[Talk]
Tutorial: Identifying bottleneck in applications [JLPC 2014]
14-37
2014
[Talk]
[Talk]
PICS - A Performance-analysis-based Introspective Control System to Steer Parallel Applications]{PICS - a Performance-analysis-based Introspective Control System to Steer Parallel Applications [No Conference 2014]
14-36
2014
[Talk]
[Talk]
Optimizing Data Locality for Fork/Join Programs Using Constrained Work Stealing [SC 2014]
14-31
2014
[Talk]
[Talk]
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance [Cluster 2014]
14-11
2014
[Poster]
[Poster]
Parallel Algorithms for Two-stage Stochastic Integer Optimization [IPDPS PhD Forum 2014]
14-09
2014
[Talk]
[Talk]
Getting Ready for Adaptive RTSs [Salishan 2014]
14-08
2014
[Talk]
[Talk]
Parallel Branch-and-Bound for Two-stage Stochastic Integer Optimization [Charm++ Workshop 2014]
14-06
2014
[Talk]
[Talk]
Power-aware Job Scheduling: Maximizing Data Center Performance Under a Strict Power Budget [Charm++ Workshop 2014]
13-62
2013
[Talk]
[Talk]
Acceleration of an Asynchronous Message Driven Programming Paradigm on IBM Blue Gene/Q [IPDPS 2013]
13-59
2013
[Talk]
[Talk]
LRTS: A Portable High Performance Low-level Communication Interface [Charm++ Workshop 2013]
13-58
2013
[Poster]
[Poster]
Scalable and Asynchronous Algorithms for Structured Adaptive Mesh Refinement [HiPC 2013]
13-57
2013
[Talk]
[Talk]
Parallel Branch-and-Bound for Two-stage Stochastic Integer Optimization (Best Paper Award) [HiPC 2013]
13-53
2013
[Poster]
[Poster]
Fast Prediction of Network Performance: k-packet Simulation [SC 2013]
{kind=link}
13-52
2013
[Poster]
[Poster]
ACM SRC: Structure-Aware Parallel Algorithm for Solution of Sparse Triangular Linear Systems [SC 2013]
{kind=link}
13-50
2013
[Talk]
[Talk]
A ‘Cool’ Way of Improving the Reliability of HPC Machines [SC 2013]
13-35
2013
[Poster]
[Poster]
Steal Tree: Low-Overhead Tracing of Work Stealing Schedulers [PLDI 2013]
{kind=link}
13-34
2013
[Talk]
[Talk]
Projections: Scalable Performance Analysis and Visualization [VAPLS 2013]
13-32
2013
[Talk]
[Talk]
Keynote: The Coming Era of Adaptive Control Systems in HPC [ICPP 2013]
13-31
2013
[Poster]
[Poster]
Towards Efficient Mapping, Scheduling, and Execution of HPC Applications on Platforms in Cloud [IPDPS PhD Forum 2013]
13-28
2012
[Poster]
[Poster]
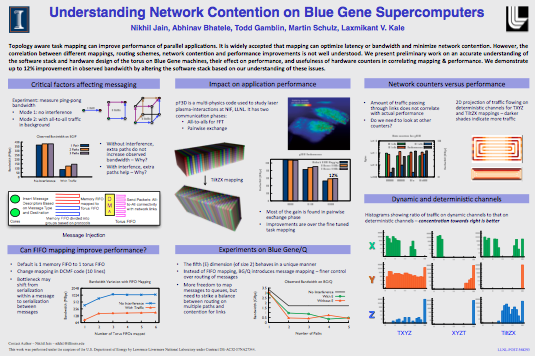
Understanding Network Contention on Blue Gene Supercomputers [LLNL Poster Symposium 2012]
{kind=link}
13-27
2013
[Poster]
[Poster]
Chizu: A Framework to Enable Topology Aware Task Mapping [LLNL Poster Symposium 2013]
13-23
2013
[Talk]
[Talk]
Tutorial: Programming with Parallel Migratable Objects [ATPESC 2013]
13-15
2012
[Talk]
[Talk]
Collectives on Two-tier Direct Networks [EuroMPI 2012]
13-12
2013
[Talk]
[Talk]
Steal Tree: Low-Overhead Tracing of Work Stealing Schedulers [PLDI 2013]
13-11
2013
[Talk]
[Talk]
Characteristics of Adaptive Runtime Systems in HPC [ROSS 2013]
13-06
2013
[Talk]
[Talk]
Adoption Protocols for Fanout-Optimal Fault-Tolerant Termination Detection [PPoPP 2013]
13-03
2013
[Poster]
[Poster]
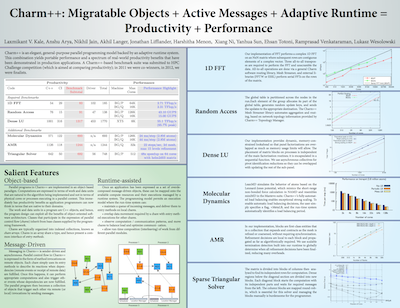
Charm++: Migratable Objects + Active Messages + Adaptive Runtime = Productivity + Performance [PSAAP Site-visit 2013]
{kind=link}
13-02
2013
[Poster]
[Poster]
Scalable Algorithms for Distributed-Memory Adaptive Mesh Refinement [PSAAP Site-visit 2013]
12-61
2012
[Talk]
[Talk]
Programming model needs at NCSA and ANL [JLPC 2012]
12-60
2012
[Talk]
[Talk]
Charj: compiler supported language with an adaptive runtime [JLPC 2012]
12-59
2012
[Talk]
[Talk]
The recovery and rise of checkpoint/restart [JLPC 2012]
12-58
2012
[Talk]
[Talk]
Fault tolerance needs at NCSA and ANL [JLPC 2012]
12-57
2012
[Talk]
[Talk]
Charm++ update [JLPC 2012]
12-56
2012
[Talk]
[Talk]
A perspective on the BigSim approach to performance prediction [JLPC 2012]
12-55
2012
[Talk]
[Talk]
Fernbach Acceptance - NAMD [SC 2012]
12-53
2012
[Talk]
[Talk]
Automated Load Balancing Invocation based on Application Characteristics [Cluster 2012]
12-52
2012
[Poster]
[Poster]
Work Stealing and Persistence-based Load Balancers for Iterative Overdecomposed Applications [HPDC 2012]
12-51
2012
[Talk]
[Talk]
Scalable Algorithms for Distributed-Memory Adaptive Mesh Refinement [SBAC-PAD 2012]
12-49
2012
[Talk]
[Talk]
Performance Optimization of a Parallel, Two Stage Stochastic Linear Program: The Military Aircraft Allocation Problem [ICPADS 2012]
12-43
2012
[Talk]
[Talk]
Assessing Energy Efficiency of Fault Tolerance Protocols for HPC Systems [SBAC-PAD 2012]
12-40
2012
[Talk]
[Talk]
Scalable Algorithms for Constructing Balanced Spanning Trees on System-ranked Process Groups [EuroMPI 2012]
12-34
2012
[Talk]
[Talk]
A Scalable Double In-memory Checkpoint and Restart Scheme towards Exascale [FTXS 2012]
12-30
2012
[Talk]
[Talk]
A Message-Logging Protocol for Multicore Systems [FTXS 2012]
12-09
2012
[Talk]
[Talk]
Composable and Modular Exascale Programming Models with Intelligent Runtime Systems [Sandia Talk 2012]
12-05
2012
[Talk]
[Talk]
Composable Libraries for Parallel Programming [PPSC 2012]
12-01
2012
[Talk]
[Talk]
Performance Issues and Techniques in Scalable Parallel Programming [C-DAC 2012]
11-61
2011
[Talk]
[Talk]
Some progress highlights for Charm++ [JLPC 2011]
11-45
2011
[Talk]
[Talk]
HPC Runtime System Software [SC 2011]
11-44
2011
[Poster]
[Poster]
Optimizing All-to-All Algorithm for PERCS Network Using Simulation [SC 2011]
{kind=link}
11-43
2011
[Poster]
[Poster]
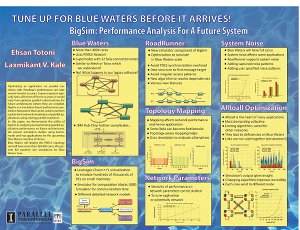
Tune Up for Blue Waters Before it Arrives [Charm++ Workshop 2011]
{kind=link}
11-38
2011
[Talk]
[Talk]
Dynamic Load Balance for Optimized Message Logging in Fault Tolerant HPC Applications [Cluster 2011]
11-36
2011
[Talk]
[Talk]
Heuristic-based Techniques for Mapping Irregular Communication Graphs to Mesh Topologies [ESCAPE 2011]
11-33
2011
[Poster]
[Poster]
Enabling Massive Parallelism for Stochastic Optimization [SC 2011]
11-31
2011
[Talk]
[Talk]
Composable and Modular Exascale Programming Models with Intelligent Runtime Systems [ASCR Programming Challenges 2011]
11-20
2011
[Poster]
[Poster]
Scaling NAno Molecular Dynamic(NAMD) on Petascale machines using Charm++ [PPL Talk 2011]
11-15
2011
[Talk]
[Talk]
Techniques for Effective Petascale Application Development based on Adaptive Runtime Systems [PPL Talk 2011]
11-14
2011
[Poster]
[Poster]
Molecular Dynamics Simulations on Supercomputers Performing 10^18 flop/s [UIUC Postdoc Symposium 2011]
10-49
2010
[Talk]
[Talk]
Exascale packages for atomistic simulations from nanoscience to drug design [JLPC 2010]
10-48
2010
[Talk]
[Talk]
Kaapi/Charm++ preliminary comparison [JLPC 2010]
10-47
2010
[Talk]
[Talk]
NUMA support for Charm++ [JLPC 2010]
10-44
2010
[Talk]
[Talk]
Hierarchical Load Balancing for Charm++ Applications on Large Supercomputers [P2S2 2010]
10-41
2010
[Talk]
[Talk]
A Study of Memory-Aware Scheduling in Message Driven Parallel Programs [HiPC 2010]
10-40
2010
[Talk]
[Talk]
Automated Mapping of Regular Communication Graphs on Mesh Interconnects [HiPC 2010]
09-33
2009
[Talk]
[Talk]
Programming Methodologies beyond petascale, based on adaptive runtime systems [JLPC 2009]
09-32
2009
[Talk]
[Talk]
Parallel composition and novel programming models [JLPC 2009]
09-26
2009
[Talk]
[Talk]
Scalable Fault Tolerance Schemes Using Adaptive Runtime Support [HPC Resilience Workshop DC 2009]
09-19
2009
[Talk]
[Talk]
Object-Based Over-Decomposition Can Enable Powerful Fault Tolerance Schemes [FTXS 2009]
09-16
2009
[Poster]
[Poster]
Topology Aware Task Mapping Techniques: An API and Case Study [PPoPP 2009]
09-15
2009
[Poster]
[Poster]
Performance Comparison of Intrepid, Jaguar and Ranger using Scientific Applications [SC 2009]
08-26
2008
[Talk]
[Talk]
Simplifying Parallel Programming with Incomplete Parallel Languages [UPCRC 2008]
08-24
2008
[Talk]
[Talk]
Some Essential Techniques for Developing Efficient Petascale Applications [SciDAC 2008]
08-18
2008
[Poster]
[Poster]
Effects of Contention on Message Latencies in Large Supercomputers [SC 2008]
08-17
2008
[Poster]
[Poster]
Automatic Topology-Aware Task Mapping for Parallel Applications Running on Large Parallel Machines [IPDPS 2008]
06-21
2006
[Poster]
[Poster]
Cosmological Simulations on Supercomputers [SC 2006]
06-20
2006
[Poster]
[Poster]
Charm++ on Cell [PPL Poster 2006]
06-19
2006
[Poster]
[Poster]
Charm++ Simplifies Programming for the Cell Processor [SC 2006]
05-27
2005
[Talk]
[Talk]
Adaptive MPI: Intelligent Runtime Strategies and Performance Prediction via Simulation [Future Technologies Colloquium Series 2005]
05-26
2005
[Poster]
[Poster]
Speeding Up Parallel Simulation with Automatic Load Balancing [PPL Poster 2005]
05-25
2005
[Poster]
[Poster]
Parallel VHDL Simulation [PPL Poster 2005]
04-19
2004
[Poster]
[Poster]
Salsa: a Parallel, Interactive, Particle-Based Analysis Tool [SC 2004]
02-16
2002
[Talk]
[Talk]
Molecular Dynamics on Thousands of Processors [SC 2002]
02-15
2002
[Talk]
[Talk]
Runtime Optimizations via Processor Virtualization [LACSI 2002]
02-12
2002
[Talk]
[Talk]
Charm++ Overview and Simple Examples [No Conference 2002]
01-07
2001
[Talk]
[Talk]
Component Frameworks for Parallel Applications [No Conference 2001]
98-11
1998
[Talk]
[Talk]
Load Balancing in Parallel Molecular Dynamics [International Symposium on Solving Irregularly Structured Problems in Parallel 1998]
96-23
1996
[Talk]
[Talk]
Charm++: A Portable Concurrent Object Oriented System Based on C++ [OOPSLA 1996]
96-22
1996
[Talk]
[Talk]
CONVERSE: an Interoperable Framework for Parallel Programming [IPPS 1996]
96-21
1996
[Talk]
[Talk]
Efficient Parallel Graph Coloring with Prioritization [PSLS 1996]
96-19
1996
[Talk]
[Talk]
Automatic Parallel Runtime Optimizations using Post-Mortem Analysis [ICS 1996]
96-18
2010
[Talk]
[Talk]
Charm++: What Have We Learned? [No Conference 2010]
96-17
1996
[Talk]
[Talk]
Threads for Interoperable Parallel Programming [LCPC 1996]
96-16
1996
[Talk]
[Talk]
A Parallel Array Abstraction for Data-Driven Objects [POOMA 1996]
95-19
1995
[Talk]
[Talk]
Efficient Implementation of High Performance Fortran via Adaptive Scheduling - An Overview [IWPP 1995]
95-18
1995
[Talk]
[Talk]
Modularity, Reuse and Efficiency with Message-Driven Libraries [PPSC 1995]
95-17
1995
[Talk]
[Talk]
Agents: An Undistorted Representation of Problem Structure [LCPC 1995]
94-06
1994
[Talk]
[Talk]
Dagger: Combining Benefits of Synchronous and Asynchronous Communication Styles [IPPS 1994]
91-10
1991
[Talk]
[Talk]
Supporting Machine Independent Parallel Programming on Diverse Parallel Architectures [ICPP 1991]